
 成人色站
成人色站
新智元报说念
裁剪:乔杨
【新智元导读】最近,Latent Space发布的播客节目中请来了Meta的AI科学家Thomas Scialom。他在节目中揭秘了Llama 3.1的一些研发念念路,并表露了后续Llama 4的更新标的。
刚刚发布的开源「巨无霸」Llama 3.1天然自带论文,但依旧激起了宏大网友热烈的深嗜心和修业欲。
Llama 3.1皆使用了哪些数据?其中有若干合成数据?为什么不使用MoE架构?
后考查与RLHF经由是何如进行的?模子评估是何如进行的?
咱们什么时候不错见到Llama 4?Meta是否会发展agent?

恰逢Llama 3.1刚刚发布,Meta科学家就现身播客节目Latent Space,秉持着开源共享的精神,对以上问题皆作出了了了的恢复。

受访者Thomas Scialom现任Meta的东说念主工智能量度科学家,指点了Llama 2和Llama 3的后考查,并干预了CodeLlama、Toolformer、Bloom、GAIA等多个口头。

以下是采访实践的节选。
Llama 3.1研发念念路
何如决定参数领域
其实LLM的参数领域的收受需要计议多种成分,包括scaling law、考查时候、GPU和硬件的不断等等。
而且,不可只计议Meta所用的硬件,还有通盘AI社区,并不是每个东说念主皆在使用H100,还有好多不同的GPU型号和显存大小。
再加上,咫尺平庸利用于推理阶段的量化本事,比如不错用FP16或FP8精度,这会转变推理和考查/微调本钱的比重。
以上这些死心成分,皆让模子领域的收受成为一个额外具有挑战性的问题。
总体而言,防御计议的是咫尺已有的算力,在Scaling Law和考查token总量的死心内,咱们进行了一些权衡,找到了一个有合适推理成果的平衡点。
之是以作念到405B这样大领域,其实原因很浮浅——咱们想作念出最好的模子,一个着实与GPT-4并排的开源模子。(咫尺是GPT-4o了)天然咫尺还莫得十足达到主见,但差距正在逐步安适。
正如小扎之前文书的,Meta囤积了越来越多的GPU,因此下一代模子将继续推广。
对于网友们所说的,无法在家里运行Llama 3.1,这很有可能是事实。但如若进行FP8量化,依旧不错用128k的荆棘文窗口在单节点上运行。
从另一个角度来看,咱们如故要寄但愿于开源社区的力量。Llama 1和Llama 2刚刚发布时,公共雷同觉得模子太大了,但两周后它就能在树莓派上运行了。
天然不可细目Llama 3.1也会和曩昔一样,但通过将模子开源,咱们但愿不错看到近似的趋势。

从头谛视Scaling Law
咱们所熟知的Scaling Law主要温雅两个维度,即模子权重和考查量,包括考查时的step、epoch和token总量等等。
基本上,论文的发现即是,模子领域是紧迫成分。因此,GPT-3犯了一个罪状——模子参数目远远超出了token总量的条目。

论文地址:https://arxiv.org/pdf/2001.08361
这也恰是之后的Chinchilla所发现和强调的,比拟来源的Scaling Law,他们更强调了考查数据token总量的紧迫性。

论文地址:https://arxiv.org/pdf/2203.15556
Chinchilla论文想要找到「算力最优化」的考查式样,觉得在有限算力的前提下,存在一个模子参数目和考查token数的最好比率。
如若你但愿在论文的基准测试中得到最优模子,那么Chinchilla自己莫得问题;但Meta要发布的旗舰模子还需要更高的推理成果。
因此,咱们收受加多考查的token数,并加多考查时长,让模子达到「过度考查」的景况。
这不适合Chinchilla定律,也会付出稀奇的算力,但咱们但愿让模子有更好的推理证实,从而更多地利用于开源社区,因此需要作念出一些突出Chinchilla定律的收受。
事实上,这亦然Llama 1的研发东说念主员所作念的事情。我所说的「不要堕入Chinchilla陷坑」即是这个兴味。
福建兄妹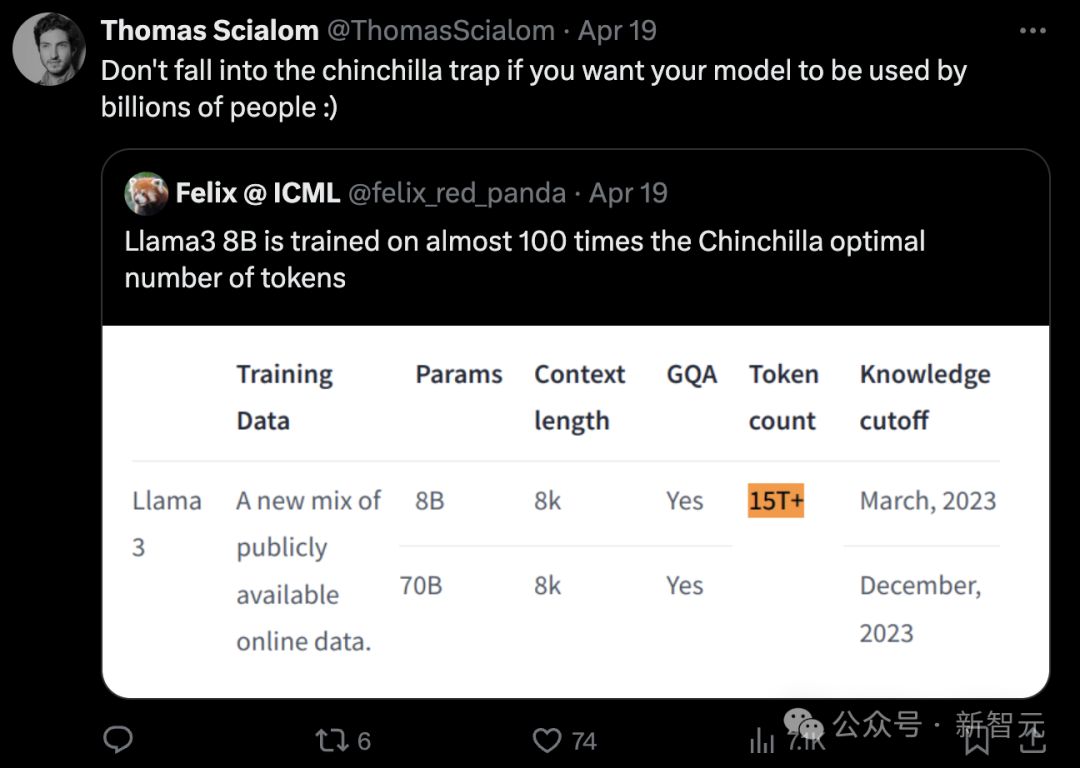
模子架构
比拟Llama 2, Llama 3的架构莫得太多变化,然则在推广数据的领域和质方位面,咱们作出了好多远程,数据集从2T token加多到15T token。
架构方面,我觉得将来会有更多纠正,以致不单是局限于Transformer。
咫尺的Tranformer架构仍然短少活泼性,比如,我觉得对每个token使用等量的算力是没故兴味的,因此还有好多量度的空间。
对于「为什么不使用MoE架构」,这个是我频繁听到的质疑,其中的原因有多个方面。
我觉得,粘稠模子只是MoE的一个特定变体,你不错把它看作唯唯一个巨匠的MoE,因此这只是一个还莫得优化的超参数良友。
但咱们咫尺正在进行一些责任,翌日可能会在这个超参数上继续探索。
对于合成数据
对于数据,我的直观是,公开互联网上充斥着过多文本垃圾,用这些token考查模子是对算力的蹧跶。
在为Llama 2执取数据时,咱们就使用Llama算作分类器,用于过滤出高质地的token,并打上主题标签,比如这段文本是和数学、法律如故政事关连,这样不错达成主题的平衡和种种性。
Llama 3的后考查过程十足莫得使用东说念主工书写的谜底,仅依靠从Llama 2得到的合成数据。
我额外看好合成数据,而且跟着模子性能普及,情况也会变得更好。
LLM的评估与纠正
咫尺的模子研发有一个趋势,即是针对基准分数进行模子的后考查纠正。
模子评估是一个绽开的量度问题,咫尺还莫得很好的谜底,尤其是面临吞并个模子有如斯多的功能。
当你试图普及模子在某个基准上的分数时,这就不再是一个好的基准了,因为可能会存在过拟合,分数普及偶然不错搬动成为相似的智力。
因此,言语模子的评估,尤其是考查后评估,是一个额外弯曲的问题。咱们尝试过好多顺次,包括用奖励模子,model-as-a-judge、使用种种化的教唆、种种化的基准测试……
我嗅觉为Llama 2进行评估要比今天容易多了,其时的模子性能比咫尺出入好多。咫尺的模子变得如斯好,以至于很难找到能击溃模子的合适prompt,进行性能比较并稽查鸿沟情况。
比较模子的其中一个好意见即是进行多轮RLHF。每次上传新模子时,只需在通盘带标注的prompt上进行采样,让新旧模子划分恢复,再自动筹备胜率。
Llama 4与Agent
Meta一经在6月开动考查Llama 4模子,而且重心可能围绕agent本事,况兼一经在Toolformer等agent器用上进行了一些责任。

论文地址:https://arxiv.org/pdf/2302.04761
但同期也要剖释到,如若莫得一个优秀的指示模子,Toolformer推广和翌日智力也会大大受限,因此咱们研发了Llama 2和Llama 3。
此外,Meta曾经在一年前发布GAIA基准,用于评估模子科罚现实全国问题的智力。
在这个基准的名次榜上,基于GPT-3的agent系统得分确凿接近于零,但GPT-4驱动的系统就有很好的获利,比如30%~40%,这其中就体现出模子的才略差距。
在我看来,agent的种种智力,比如函数调用、慑服复杂指示、事前考虑、多体式推理等等,和模子的这种才略差距是近似的。

论文地址:https://arxiv.org/pdf/2311.12983
咫尺有了豪阔刚劲的Llama 3成人色站,我将从头专注于agent的构建。如若能达成邃密的模子互联,变成一个复杂的agnent系统,将得到几个数目级的推广,从而达成考虑、回溯、网页导航、代码实行等多种功能。